技术原理&术语解释
抽象语法树 Abstract Syntax Tree (AST)
概述
抽象语法树是编译过程中构建的一种中间数据结构。编译过程通常经历词法分析、语法分析、语义分析、中间代码生成、机器码生成等多个步骤。其中,抽象语法树是语法分析的结果,语义分析的载体。大部分程序分析和语义理解的技术都是基于对抽象语法树的分析。相比之下,源代码更贴近自然语言的表达,不利于机器理解,而且噪音较多;机器码则面向系统底层运行,高度优化和抽象,已经不能很好地反映人表达的逻辑形式。
各个编程语言会对应不同的抽象语法树定义。我们在各个语言抽象语法树的基础上,进一步提炼出统一的、编程语言无关的通用抽象语法树(universal abstract syntax tree, UAST)。我们在 UAST 上执行统一的算法和模型,而不必为每一门编程语言适配不同的算法和模型。在本文档中,思码逸 Merico 的抽象语法树(AST)通常即指代通用抽象语法树(UAST)。
示例
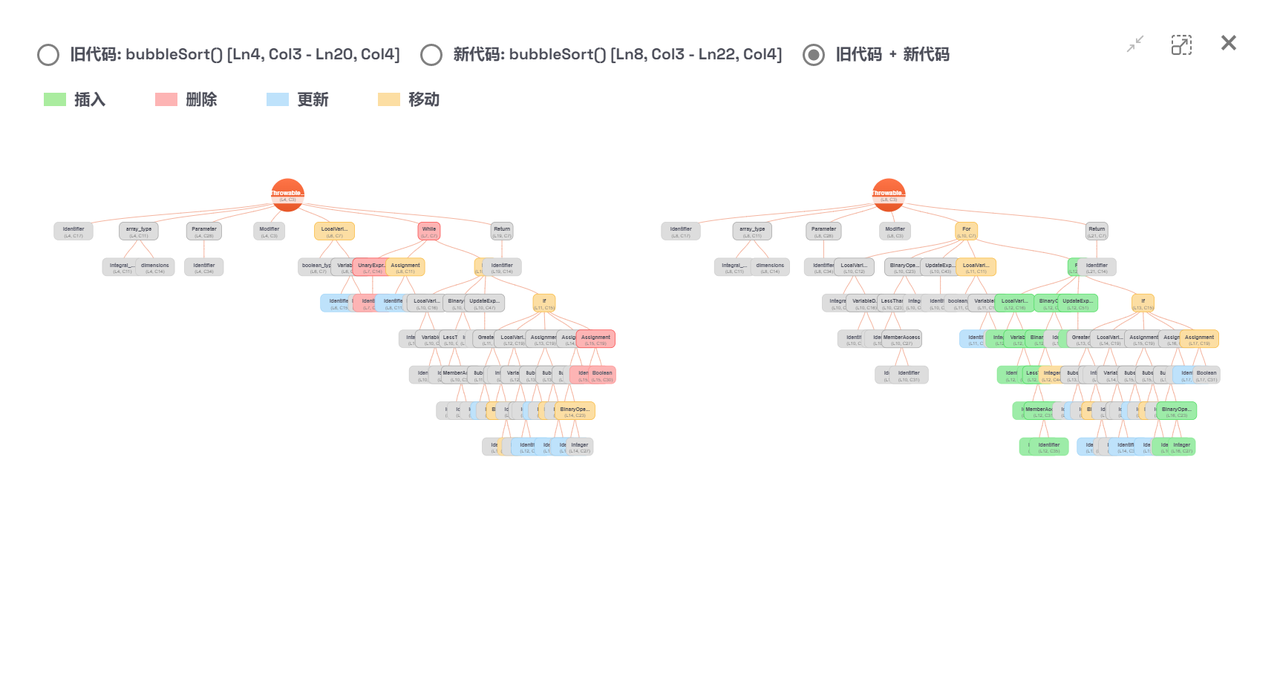
抽象语法树示例图片: 左侧为commit提交前的代码抽象语法树,右侧为commit提交后的代码抽象语法树
代码当量 Equivalent Lines of Code (ELOC)
指标概述
代码当量是衡量开发者修改代码的工作量的指标。与代码行数(LOC)、提交个数(NOC)等简单指标相比,基于抽象语法树(AST)计算的代码当量能更准确地反应修改代码的工作量。
指标优势
代码行数是简单且常用的衡量代码工作量的指标。但是它的缺点很明显,例如:容易受到代码风格、换行习惯、注释、格式化操作等的干扰;无法识别出对代码的实际修改,简单的复制粘贴、移动代码块等会产生大量的行数增删变化。
代码当量很好地解决了这些问题。它将源代码解析成抽象语法树这种更能体现代码语法结构、代码本质的形式,通过比较代码修改前后抽象语法树之间的变化,来计算一次修改行为的工作量。
首先,代码被解析为抽象语法树后,消除了代码书写风格、注释格式等与代码逻辑无关因素的干扰。
其次,基于树结构的比较,能很好地识别移动代码(Move)、更新代码(Update)等操作,为它们赋予更合理的工作量。同时,在抽象语法树的基础上,代码当量能通过简单的语义分析,区分代码中的“数据”和“逻辑”,弱化非关键的“数据”修改,强化“逻辑”修改。
更进一步地,代码当量还有很多智能调节机制来处理实际开发中常见的场景,例如对重复代码的调节、排除由开发工具自动生成的代码、排除第三方库的代码、平衡不同编程语言之间的差异等。
计算原理
代码当量的基础计算过程如下:
- 分别将修改前的代码和修改后的代码解析为抽象语法树(AST)。
- 使用tree diff算法计算将修改前的AST转换成修改后的AST的编辑脚本(Edit Script)。编辑脚本里包括四种对树的编辑操作:插入、删除、移动、更新。
- 对于被编辑的抽象语法树节点,根据它的节点类型和编辑操作类型,分别进行加权计算。
- 最后,对所有被编辑的节点的加权结果进行求和,即为这次修改的代码当量。
- 计算过程中如触发各种当量调节规则,如重复代码识别、第三方库识别、自动生成代码识别等,会根据当量调节规则扣减当量。
算法图示
下图简单演示了这个过程如何从代码的修改计算出代码当量的数值。

实例对比
例 1
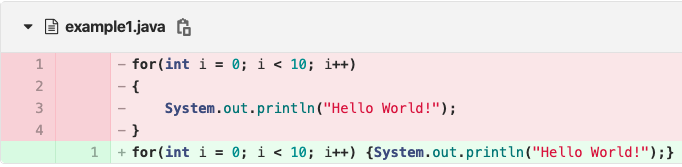
代码行数很容易因为简单的修改而显著增加。比如下面的代码变动,尽管代码修改后本质并没有发生变化,这个修改仍会产生 1 行添加和 4 行删除。
而单纯的格式变化对 AST 没有影响,此段代码修改前后 AST 是相同的,因此其代码当量为 0。
例 2
代码行数不擅长检测代码块的移动。比如下面的代码变动,简单地交换类中函数的顺序会产生 4 行添加和 4 行删除。
但是从抽象语法树的角度,这次修改只是改变了 myMethod()函数对应节点在其父节点下的顺序,该节点本身未发生任何修改。因此修改 myMethod()的代码当量为 0。

例 3
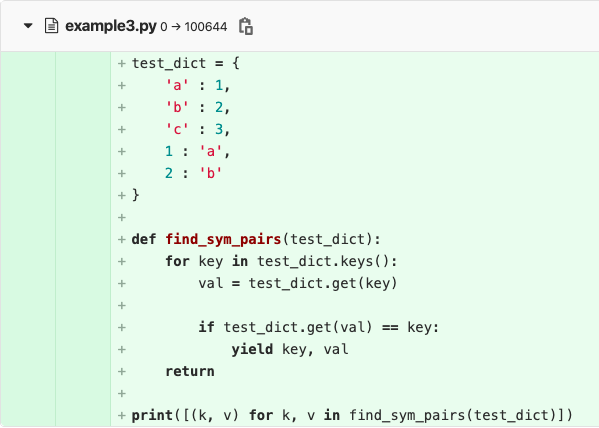
代码行数无法区分不同性质的代码的工作量。考察以下 Python 代码,它的功能是在给定的字典中找到对称对。
测试数据test_dict和实际功能函数find_sym_pairs()贡献了相等数量的行数(7 行),然而这两段代码所包含的工作量显然不同。
通过识别代码语义,可以区分不同性质的代码内容,进而更合理地评估相关变更所包含的工作量。
例 4
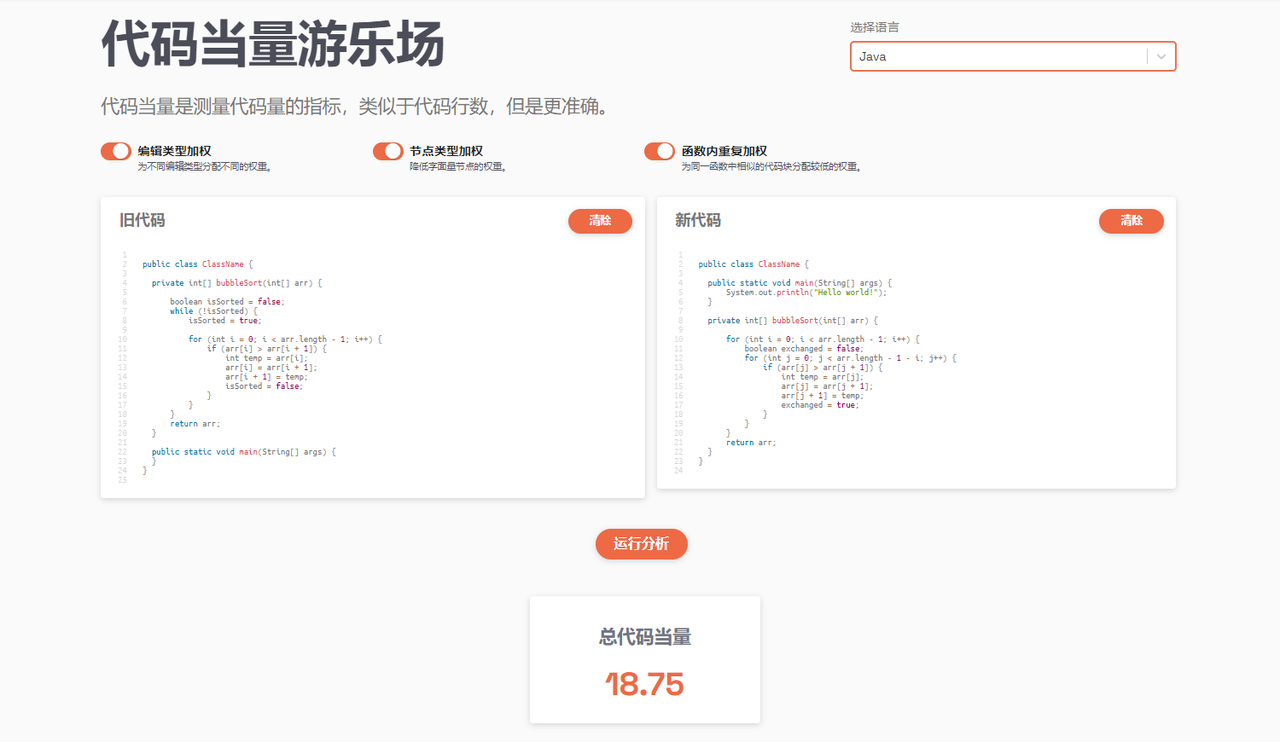
以 ELOC Playground 中的Java示例代码为例,从旧的代码片段变为新的代码片段,产生的当量为18.75:
当量分析过程中,识别到如下函数对:
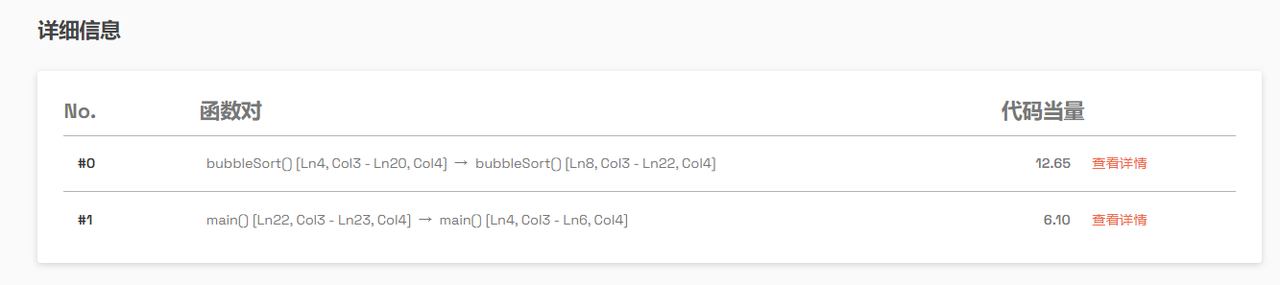
可以看到各函数对从旧代码到新代码的变化过程中,产生了代码当量,点击 查看详情 按钮,可以查看每个函数对的AST解析展示:
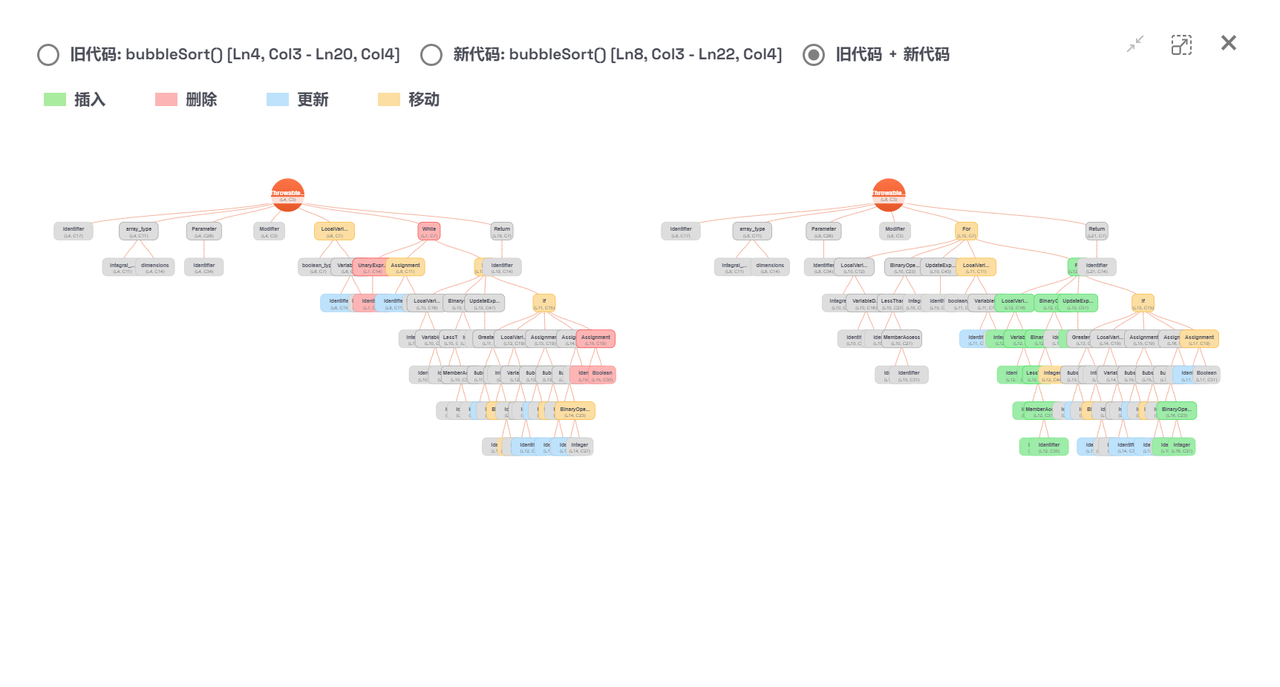
可以看到旧代码片段和新代码片段分别被解析为了对应的抽象语法树(AST),抽象语法树中包含不同类型的AST节点。并且在从旧树到新树的变化过程中,各个AST节点有不同的编辑类型。
在上图中,各AST节点上标识了其节点类型,如:Identifier,Parameter,Modifier;并用不同颜色标识出不同的AST节点编辑类型,包括:插入,删除,更新,移动。
不同的 AST节点类型 各有其当量计算权重,不同 AST节点编辑类型 亦各有其当量计算权重。可以通过分别关闭三种加权开关中的一个来了解主要的三类加权对当量分析的影响。
以以上 ELOC PlayGround 里自带的Java代码示例为例:
| 编号 | 编辑类型加权 | 节点类型加权 | 函数内重复加权 |
|---|---|---|---|
| 1 | 打开 | 打开 | 打开 |
| 2 | 关闭 | 打开 | 打开 |
| 3 | 打开 | 关闭 | 打开 |
| 4 | 打开 | 打开 | 关闭 |
编辑类型加权:为不同编辑类型分配不同的权重。
节点类型加权:根据节点类型分配权重。
函数内重复加权:为同一函数中相似的代码块分配较低的权重。
在思码逸深度代码分析系统企业版中,代码当量计算过程里除了以上节点级别的当量调节规则外,还包含了函数级别、文件级别、提交级别的当量调节规则,通过抽象语法树的节点变化和各级别当量调节规则的共同作用,最终得到各次提交的代码当量。
代码影响力 DevRank
指标概述
代码影响力是综合了函数的代码当量和函数调用关系的指标,也就是论文里提到的 DevRank。为便于理解,我们以百分比的形式计算该指数,可以直观理解为贡献比例。
其中调用关系反映函数间相互依赖的关系。越多函数直接或间接地依赖于某个函数,那么该函数的开发影响力就越高;也意味着,如果该函数作出修改,回归测试的范围相应越大,即修改成本较高。通常来说,这类函数的重要性也越高。
函数之间带历史的依赖关系构成的图被称为“调用-提交关系图(Call Commit Graph)”。代码影响力即是在这张图上运用类似 PageRank 的图算法计算出的。(公式详见我们在 FSE '18 上发表的论文)。
指标解读
代码影响力越大代表该提交或者该开发者贡献代码对整个项目代码库的影响越广,需要引起更多的关注,如确保函数被有效的测试覆盖、注释覆盖以及代码评审。
指标导航
工程师表现 > 贡献者排行 > 代码影响力榜
示例
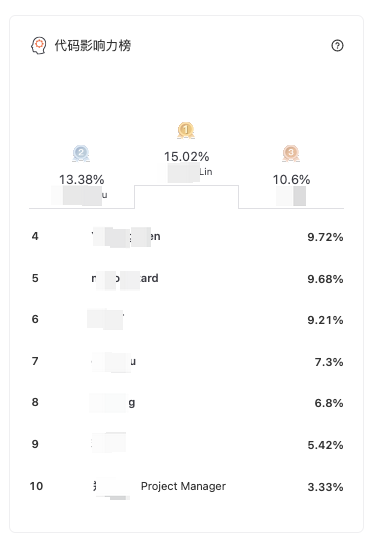
开发价值 Dev Value
指标概述
目前的开发价值数值上即为代码影响力。
开发价值的改进方向:开发价值旨在成为综合了代码当量、代码影响力和工程质量的综合指数,更全面的反映开发的价值。其中工程质量指标包括不重复度、测试覆盖度、注释覆盖度、代码问题数、圈复杂度等。
指标解读
开发价值越高意味着代码产出、影响力、质量的综合评分越高。不能一味追求高产出而把代码写的过于复杂、冗余,也不能只注重代码质量而降低开发效率,需要平衡效率和质量达到价值最优。
指标导航
无
代码质量问题 Code Quality Issue
指标概述
代码质量问题是思码逸通过部分自定义的代码质量规则和集成一些开源的代码质量检查工具检测出来的。目前已集成的开源工具包括 SonarQube、Cppcheck。
指标解读
质量问题按类型分为六类:
错误(Bug): 即代码中存在的明显错误,破坏了您代码的正常运行,需要立即修复。
漏洞(Vulnerability): 即代码中容易受到攻击的细节,需要您提起关注。
异味(Code Smell): 即代码中可能导致深层次问题的症状,例如冗长的参数列表、过长或过短的变量名。如果您扫描出此类问题,说明您的代码有些混乱且难以维护。
安全热点(Security Hotspot): 存在对安全性敏感的代码。
性能(Performance): 该问题很可能引起系统运行时的性能问题。
可移植性问题(Portability): 代码有局限性,不易移植到其他环境中。
质量问题按严重性分为五个级别,从高到低分别是:
阻塞(Blocker): 很可能会影响生产环境正常运行的错误,例如:内存泄漏,未关闭的 JDBC 链接等等。必须立即修复代码。
严重(Critical): 可能会影响生产环境正常运行的错误,也可能是代表安全漏洞的问题,例如:空的 catch 块,SQL 注入等等。必须立即检查代码。
主要(Major): 严重影响开发人员生产力的质量缺陷,例如:无效的代码逻辑,重复的代码,未使用的参数等等。
次要(Minor): 稍微影响开发人员生产力的质量缺陷,例如:行不应太长,“ switch”语句应至少包含 3 种情况等等。
提示(Info): 仅为提示信息。
查看测出的代码质量问题时,应根据项目特性和实际需求,约定项目的代码规范,关注重点问题,屏蔽轻微问题的干扰。建议根据问题的严重程度,按时间节点或迭代节奏明确相应的解决比例要求。日常开发中,要适时进行 Code Review。 外部链接参考:https://docs.sonarqube.org/latest/user-guide/issues
指标导航
技术债监控 > 代码问题
示例代码
function seek(input) {
let target = 32; // 不符合规范的写法
for (let i of input) {
// 不符合规范的写法
if (i == target) {
return true;
}
}
return false;
}这段代码的第 2、3 行存在严重程度为“主要”的代码异味:Unchanged variables should be marked "const"。在 Javascript 中,对于初始化后其值就不再改变的变量,应该用const明确地表示“该变量不会、也不应该被修改”。这样使得代码更加清晰,易于维护。
代码不重复度 Dryness
指标概述
代码不重复度体现的是项目中函数的不重复程度。
对于当前项目中的函数,我们使用基于 Minhash 和 LSH 的文本查重算法,寻找出相似度较高的函数,认为它们互相之间是重复的函数,并按重复关系分组。不重复度即为:无重复的函数数目占项目中总函数的比例。
指标解读
代码不重复度越高,意味着项目中重复的函数较少,更加符合“Don't repeat yourself”原则,代码的可维护性较好。
通常建议对于重复或者相似的逻辑,将其提炼成函数或者抽象出可以公用的基类,从而增加可读性,也能减少需要的单元测试数目。但同时也要在不重复度和函数圈复杂度上做好平衡,避免将一段代码封装得过于复杂。
指标导航
技术债监控 > 代码重复
示例代码
def hello():
print('Hello world')
def remove_node_meta_v1(self, node_meta):
"""
Remove indexed function(node_meta)
"""
if node_meta not in self._node_meta_mh:
return
mh = self._node_meta_mh.pop(node_meta, None)
self._lsh.remove(node_meta)
def remove_node_meta_v2(self, node_meta):
"""
Remove indexed function(node_meta)
"""
if node_meta not in self._node_meta_mh:
return
mh = self._node_meta_mh.pop(node_meta, None)
if not mh:
return
self._lsh.remove(node_meta)本例中有三个函数 hello(),remove_node_meta_v1(),remove_node_meta_v2()。
其中remove_node_meta_v1()和remove_node_meta_v2()非常相似,他们会被判定为重复函数;而hello()则没有与之相似的函数。
因此本例的代码不重复度为 1 / 3 = 0.33。
静态测试覆盖度 Static Test Coverage
指标概述
被测试函数覆盖的函数占项目中非测试函数总数比例。
对于各个编程语言,我们收集了一些主流测试框架的路径要求或者命名规范,根据文件路径判断某文件是否是测试文件。如果该文件是测试文件,那么里面定义的函数就归到测试函数的类别。
然后根据静态分析,找到测试函数中所调用到的函数,认为这些函数即为被测试覆盖。这里的调用关系具有传递性。即,如果函数 A 调用了函数 B,而测试函数 Test 里调用了 A,那么 A 和 B 都视为被 Test 所覆盖。
静态测试覆盖度 = 被测试覆盖的函数数目 / 项目中非测试函数的总数 = 被测试覆盖的函数数目 / (被测试覆盖的函数数目 + 未被测试覆盖的函数数目)
指标解读
测试覆盖度数据越高,意味着项目中被测试覆盖的函数比例越多,代码的可靠性较好。
从长远来说,提升测试覆盖度,可以提高代码质量,减少维护成本,降低重构难度。但是测试覆盖度并非越高越好,它会加大开发者的工作量,需要考虑投入产出比。
建议对于核心函数、复杂函数增加单元测试覆盖,同时应按照测试框架的要求规范测试文件、测试函数的命名。而对于项目整体,需关联效率和其他质量指标,综合分析,找到平衡点。
指标导航
技术债监控 > 单测覆盖度
示例代码
# my_functions.py
def my_add(a, b):
return a + b
def my_sub(a, b):
return a - b# test_my_functions.py
def test_my_add():
assert my_add(1, 2) == 3本例中共有两个文件共三个函数。其中test_my_functions.py会被识别出为测试文件,test_my_add()即为测试函数。test_my_add()中调用了my_add(),my_add()即为被测试所覆盖的函数。my_sub()未被测试函数调用,它未被测试覆盖。
本例的测试覆盖度为 1/2 = 0.5
注释覆盖度 Documentation Coverage
指标概述
有注释的函数占项目中总函数个数的比例。
函数的注释包括以下几种情况:
- 位于函数内部的注释
- 位于函数上方,紧挨着函数的注释
- Python 的文档字符串(Docstring)
指标解读
注释覆盖度数值越高,意味着项目中有注释的函数数目越多,代码的可读性较好。
通常建议结合业务逻辑和函数复杂度,梳理项目的注释规范,结合业务特征明确注释覆盖度标准,为复杂的函数适当添加注释。
指标导航
技术债监控 > 注释覆盖度
示例代码
class MyClass:
def __init__(self, name):
"""
Init with a name
"""
self.name = name
def greet(self):
message = 'Hello, ' + self.name
# print a greeting message
print(message)
# This method with return the name
def get_name(self):
return self.name
def get_upper_name(self):
return self.name.upper()
# get name with lower case
def get_lower_name(self):
return self.name.lower()在这个代码片段中共有 5 个函数 __init__(), greet(), get_name(), get_upper_name(), get_lower_name()。
其中有注释的函数为:
__init__(): 有符合 Python 定义的文档字符串greet(): 函数内部有注释get_name(): 函数上方有紧挨着的注释
没有注释的函数为:
get_upper_name(): 没有任何注释get_lower_name():上方的注释与函数分离,不符合格式要求
因此这个片段的注释覆盖度为 3/5 = 0.6
函数圈复杂度 Function Cyclomatic Complexity
指标概述
圈复杂度也称为条件复杂度或者循环复杂度,是一种衡量代码复杂度的标准。函数的圈复杂度数值上为函数中线性独立路径的个数。计算方式为函数控制流程图中条件判定节点的数量加一。
指标解读
当函数中的条件判断语句越多,意味着函数的逻辑越复杂,出错风险和维护难度便会增加。圈复杂度较高的函数需要引起更多的关注,如确保函数被有效的测试覆盖,或者适时重构以降低圈复杂度。通常建议圈复杂度保持在 10 以下。
降低圈复杂度的技巧通常有:
- 将部分逻辑拆分成独立的函数
- 优化算法
- 简化、合并条件表达式
- 用合理的数据结构(如键值对)替代连续的
if-else或者switch语句
指标导航
技术债监控 > 选择具体代码库 > 函数复杂度 > 圈复杂度
示例代码
def hello(name):
print('Hello,' + name)
def max2(a, b):
if a > b:
return a
return b在函数hello()中,条件判定节点个数为 0,因此它的圈复杂度为 1。
在函数max2()中,有一个条件判定节点 If,因此它的圈复杂度为 2。
模块性 Modularity
指标概述
是衡量当前项目中函数调用关系的模块化程度的指标。
通过分析项目当前状态中函数间的调用关系图(Call Graph),基于图算法找出调用关系图的最优划分,计算出在这个最优划分下图的模块度(详见https://en.wikipedia.org/wiki/Modularity_(networks)),即为项目的模块性。 具体公式为 https://en.wikipedia.org/wiki/Modularity_(networks)#math_3。
指标解读
模块性反映了项目函数间调用关系的紧密程度。数值越高,即调用关系越紧密,项目内聚程度越高。
模块性分数的高低通常仅作为参考,需要结合用户项目自身的业务逻辑来看,有的项目或功能就是高内聚的,模块性就高,有的项目作为公共库主要被其他项目使用,模块性可能就相对偏低。
目前的模块性反映问题不够直观,思码逸将对本指标进行改进。
指标导航
项目表现 > 质量报表 > 模块性
项目表现 > 同行对比 > 质量 > 模块性